
A few weeks ago, Aaron Barzilai (@basketballvalue on Twitter) of HerHoopStats posited a wonderful little idea when ESPN’s Adrian Wojnarowski and his former protégé, Shams Charania, both tweeted out news of the Lakers’ signing mercurial free agent Michael Beasley within seconds of each other. What if we could have some sort of automated method to keep track of the score on similar news hits from both Shams and Woj?
To which, I responded: what if we used a Twitter bot to do exactly that? Having never created a Twitter bot myself, I thought it would be a fun learning opportunity. And it was! All in all- from setup to finish, the project took about 12 hours to code up and get running live. I used the Tweepy package for Python in order to interface with Twitter’s API and Heroku to host my bot and keep it running around the clock.
There were two key pillars in developing this – the bot itself and the actual processing of the tweets, which makes up the fundamental functionality of the bot. Now, creating a Twitter bot is fairly simple enough on the setup side. Start by setting up an account to host your automated little digital friend, and then go to Twitter’s application management portal (https://apps.twitter.com) to set up your app. Fill out the forms, check off the agreements, and then you’ll be able to get the necessary authentication codes in the “Keys and Access Tokens” tab.
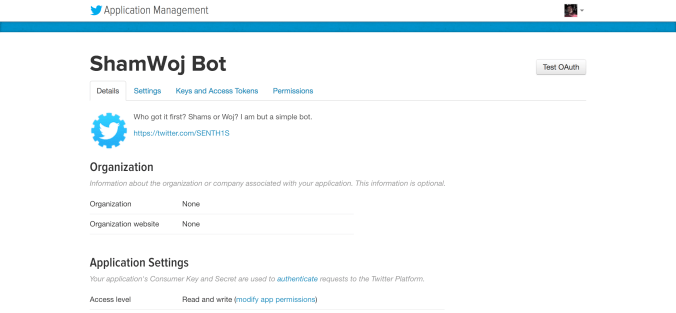
Boom! We’re now ready to dive into the code. Now, this is the first ever code-through that I’ve written, so bear with me, and we’ll be able to hopefully learn together. I’ll go step by step through each block of my script (you can find the full GitHub repository at this link), and attempt to outline the thought processes behind each line. All the while, hoping upon hope that you don’t cringe too hard at any poorly written code. Excited yet?
Initialization
The first step – as with any good program – is setting up the initial imports. Make sure that you’ve installed the Tweepy package (pip is a nice resource here!) and you’ll be ready to get going. Tweepy is one of the best documented and easy-to-use packages around for connecting to Twitter’s API, making it a natural choice for our use case.
#!/usr/bin/env python # -*- coding: utf-8 -*- # install and include python-Levenshtein import fuzzywuzzy.fuzz as fuzz import tweepy import time as timer from datetime import datetime, timedelta
As we’ll be dealing with text parsing, the first couple lines help ensure that we use the appropriate character encoding when our script reads in the various tweets. The third comment statement is moreso a reference, just for optimization purposes. It’ll be good practice going forward for the text matching that we’re going to be doing to have this module installed (more on Levenshtein matching later).
Fuzzy Wuzzy is a string matching module developed by the folks over at SeatGeek (make sure to pip this one as well). You can read more about it in their own post here, but the gist is this: it was developed in order to help them compare and match strings and labels that may contain the same content but could be written slightly differently in various instances (i.e. Gary Trent, Jr. versus GARY TRENT JR) – a “fuzzy” string, so to speak, hence the name of the package. The other two import statements should be fairly self-explanatory – a timer to put our bot to sleep and wake it back up again and the datetime package to compare tweet timestamps.
The next step is to initialize the authentication and connection to Twitter’s API.
#################################### # Initialize Authentication Tokens #################################### consumer_key = '[insert your key here]' consumer_secret = '[insert your token here]' access_token = '[insert your key here]' access_token_secret = '[insert your token here]' auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tweepy.API(auth)
Not a whole lot particularly interesting happening here. This is just a few lines of grunt work needed for Twitter to allow Tweepy to access its secret stashes. The “api” object is going to be the primary means of grabbing information off of Twitter. Just picture that the “api” object is Kawhi Leonard (the healthy version, I suppose) rearing to grab any basketball (the tweet in this metaphor, I think) in the vicinity. Once he’s been authenticated, we can let him into the game. (And since there’s a non-zero chance that Kawhi might be a robot anyway, this metaphor worked better than I expected when I started writing that last sentence).

The Supporting Cast
Anywhoo, less rambling analogies and more code, Senthil, you’re probably thinking to yourself. The next step we’re going to do is set up a couple of helper data structures/variables that will come in handy down the line. Now, I fully recognize that the dictionary you’re about to see below can seem slightly unwieldy and may be better being read in from a separate table or source. It made a marginal amount of sense to me though to keep it hard-coded in for write-up purposes, so that everything is laid out in the same page.
###########
# Helpers
###########
# A probably non-comprehensive mapping of team and city nicknames to official city names
teams_map = {"Hawks": "Atlanta", "Celtics": "Boston", "Nets": "Brooklyn", "Hornets": "Charlotte", "Bulls": "Chicago",
"Cavaliers": "Cleveland", "Mavericks": "Dallas", "Nuggets": "Denver", "Pistons": "Detroit",
"Warriors": "Golden State", "Rockets": "Houston", "Pacers": "Indiana", "Clippers": "Los Angeles",
"Lakers": "Los Angeles", "Grizzlies": "Memphis", "Heat": "Miami", "Bucks": "Milwaukee",
"Timberwolves": "Minnesota", "Pelicans": "New Orleans", "Knicks": "New York", "Thunder": "Oklahoma City",
"OKC": "Oklahoma City", "Magic": "Orlando", "LA": "Los Angeles", "76ers": "Philadelphia",
"Suns": "Phoenix", "Trailblazers": "Portland", "Trail blazers": "Portland", "Trail Blazers": "Portland",
"Blazers": "Portland", "NOLA": "New Orleans", "Kings": "Sacramento", "Spurs": "San Antonio",
"SA": "San Antonio", "Raptors": "Toronto", "Raps": "Toronto", "Jazz": "Utah", "Wizards": "Washington",
"Wiz": "Washington", "Clips": "Los Angeles", "ATL": "Atlanta", "BOS": "Boston", "BKN": "Brooklyn",
"CHA": "Charlotte", "CHO": "Charlotte", "CHI": "Chicago", "CLE": "Cleveland", "DAL": "Dallas",
"DEN": "Denver", "DET": "Detroit", "GSW": "Golden State", "HOU": "Houston", "IND": "Indiana",
"LAC": "Los Angeles", "LAL": "Los Angeles", "MEM": "Memphis", "MIA": "Miami", "MIL": "Milwaukee",
"MIN": "Minnesota", "NOP": "New Orleans", "NO": "New Orleans", "NY": "New York", "NYK": "New York",
"ORL": "Orlando", "PHI": "Philadelphia", "PHO": "Phoenix", "PHX": "Phoenix", "POR": "Portland",
"PDX": "Portland", "SAC": "Sacramento", "TOR": "Toronto", "UTA": "Utah", "WAS": "Washington",
"Sixers": "Philadelphia", "Philly": "Philadelphia"}
# Specify duration/refresh interval to check back on
d = datetime.today() - timedelta(hours=3)
First things first, that monstrosity of a dictionary. What’s the deal there? Well, let’s think about the text processing we’re going to be doing. We’re dealing with news hits mainly about athletes who are connected to various sports teams. We’re also not using any sort of fancy machine learning or natural language processing algorithms (a natural follow-up to this project, and one that I hope to utilize to improve the bot in the future!). This means we need to establish a structure and a set of rules around how we compare two tweets.
One of the lowest hanging fruits here is the use of team names and shorthands. I.e. Michael Beasley signed with Los Angeles earlier today. LeBron has a meeting scheduled with Philadelphia. In both sentences, the author is referring to an organization, but depending on the whims of the wordsmith (and Woj has proven to be quite the adept quipper), they could use the team name, the city name, the shorthand, or some combination. So in order to not get lost in artificial differences between tweets, we will use the above dictionary to standardize all team references (as best as possible) to be the full city name.
The second helper object is more straightforward. Using the datetime module, every time this script is run, we are only going to look at tweets in the last three hours. This is useful for two main reasons. Since the script will be run every three hours anyway, there’s no need to consider posts before that scope of time. Additionally, since Twitter doesn’t like it when bots start going buckwild with the queries, this will help us manage the overall usage of Twitter’s API and only consider the relevant pool of tweets.
Okay, last helper before we get to the star of the show, I promise. After all, every LeBron James needs a little Birdman, a little James Jones, a little JR Smith (who is decidedly *not* the time variable in this metaphor – ba dumm tssss). This one is a function though!
# Helper function for stripping artificially similar language
def content_stripper(s):
# remove punctuation that connects two words directly
s = s.replace("-", " ")
s = s.replace("/", " ")
s = s.replace(".", " ")
s = s.replace(",", " ")
# standardize team names to cities
for word in s.split(' '):
if word in teams_map:
s = s.replace(word, teams_map[word])
# Permutations of "league sources say..."
if "League sources tell" in s:
s = s.replace("League sources tell", "")
if "league sources tell" in s:
s = s.replace("league sources tell", "")
if "League source tells" in s:
s = s.replace("League source tells", "")
if "league source tells" in s:
s = s.replace("league source tells", "")
if "league sources said" in s:
s = s.replace("league sources said", "")
if "sources: " in s:
s = s.replace("sources: ", " ")
if "Sources: " in s:
s = s.replace("Sources: ", " ")
if "sources" in s:
s = s.replace("sources", "")
if "Sources" in s:
s = s.replace("Sources", "")
# Permutations of certain deal type parameters
if "free agent" in s:
s = s.replace("free agent", "")
if "Free agent" in s:
s = s.replace("Free agent", "")
if "trade" in s:
s = s.replace("trade", "")
if "agreed" in s:
s = s.replace("agreed", "")
if "deal" in s:
s = s.replace("deal", "")
return s
Keeping with the theme of the above dictionary, we’re going to again do our best to reduce the amount of artificial differences in tweets that might just come from a variance in sentence construction. This means removing unnecessary punctuation and applying our team name standardization from earlier. There very likely are better ways to do this. Be a better coder than me, ladies and gents.
Just as well, 99.9% of tweets (an unofficial number, but pretty close I think) from Woj and Shams that are about key pieces of NBA news are sourced. This means all the relevant tweets will contain some variation of “sources said…” or “according to a source…”. These phrases add nothing relevant to the main content in the tweet and are not pertinent to evaluating the actual similarities between two tweets. So we’ll run our strings through this helper function and use the replace function to just cut them out. Cut them out of our lives like Russell Westbrook did with Kevin Durant.
The Shamwow ShamWoj Function
Ah, finally. This is what we’ve been building up to this whole time. If you’ve been able to make it to this point and bear with me through all the terrible metaphors, just know that I appreciate you. There are quite a few lines to unpack here, so I’m going to break this function up into smaller blocks and take it step-by-step, starting with the initial pull from Twitter.
####################################
# Shams-Woj Similarity Competition
####################################
# Primary function for comparing Shams to Woj... Who will come out on top?
def shamwoj():
# Aggregate all Woj tweets within last duration, but only if they're news hits
woj_tweets = []
for status in tweepy.Cursor(api.user_timeline, id="wojespn", tweet_mode="extended").items(100):
if ("source" in status.full_text) or ("sources" in status.full_text) or ("Source" in status.full_text) or ("Sources" in status.full_text):
if status.created_at >= d:
woj_tweets.append(status)
# Aggregate all Shams tweets within last duration, but only if they're news hits
sham_tweets = []
for status in tweepy.Cursor(api.user_timeline, id="ShamsCharania", tweet_mode="extended").items(100):
if ("source" in status.full_text) or ("sources" in status.full_text) or ("Source" in status.full_text) or ("Sources" in status.full_text):
if status.created_at >= d:
sham_tweets.append(status)
The tweepy.Cursor call is the method by which we can access a user’s timeline. From Tweepy’s own documentation, a Cursor object exists in order to handle the leg work of managing the pagination of tweets, direct messages, replies, etc. Using the Cursor, we can immediately call up all the tweets (“api.user_timeline”) as long as we provide the ID of the user. The tweet_mode parameter is specified just to make sure we don’t unintentionally cut out any text from a tweet.
Of course, with each pool of tweets, we can immediately do some preliminary filtering. First, we only want news hits, and according to what we know about the semantics of such tweets, most of the time, they contain the word “sources” in some form. It’s cool if Shams just took an exam or ate ice cream, but that’s not really what we are concerned with. Second, we will make use of our time scope helper object from earlier and check that the only tweets we add into the pool for each reporter are within the last three hours. Once a tweet passes those two filters, it can be added to our lists.
Each tweet object contains numerous features such as the content of the tweet, the timestamp, the user, etc. so I highly encourage you to print out a few and explore it for yourself. However, as you can see, we really only need the text from the tweet as well as the timestamp.
# Iterate through Shams/Woj tweets to find similar tweets
for ss in sham_tweets:
for ww in woj_tweets:
# Get the content out of the tweet objects
s = ss.full_text
w = ww.full_text
# Clean the tweets by stripping out artificially similar language
s = content_stripper(s)
w = content_stripper(w)
# Get similarity scores and establish similar tweets
simtoken = 0
if fuzz.token_set_ratio(s, w) > 50:
# Similarity established beyond reproach
if fuzz.token_set_ratio(s, w) >= 66:
simtoken = 1
We’re going to loop through each tweet in one bucket and compare it to the all the tweets in the other bucket. So keep this main for loop in your mind because it’s not going away any time soon. After we get the full text of the tweets, we’ll first run it through our content_stripper function. Boom – proccessed (Joel Embiid says hi).
Here’s the real fun part. Let’s call upon FuzzyWuzzy to find the similarity between two strings. I highly recommend reading the entire SeatGeek post on the FuzzyWuzzy module linked above, but let’s briefly take a few seconds to understand what’s happening here. The underlying principle and most basic way to compare differences between two strings is using what’s known as the “edit distance.”

Essentially, what is the character-by-character difference between two strings and the minimum number of edits required to transform one string into the other? This works great when we’re just comparing names or short strings, but you can see where it might break down when we have strings as long as full sentences.
In order to compare full sentences, we need to be prepared for a host of contingencies, such as: partial strings (“Lakers” versus “Los Angeles Lakers”), out of order strings (“Bucks and Pistons” versus “Pistons and Bucks”), among others. In order to account for this, we will use FuzzyWuzzy’s token_set_ratio method. In this, both strings get tokenized first (split into the constituent words), then split into combinations of the common intersection and the “outer”section (Is that a word? Let’s pretend it’s a word.), and finally, those combinations get compared to each other, making for a far more robust text matching algorithm than simple edit distance. Blessed be those who do great work and then open-source it for the rest of the world to enjoy.
So, back to the code. The token_set_ratio method outputs a value between 0 and 100 (with 100 being a perfect match). We only want to even think about looking into strings that have at least a halfway similarity. If they’re at least two-thirds similar, it’s highly likely that we’ve got a match on our hands (at least from the testing that I was able to do – your mileage may vary). The simtoken variable serves as our flag to store whether or not we have found the two tweets to be similar.
# If similarity score isn't high enough, check the proper nouns in the tweets
elif fuzz.token_set_ratio(s, w) < 66:
# Initialize objects for keeping track of proper noun overlap
wupp = []
supp = []
strue = 1
wtrue = 1
# Insert all proper nouns into their respective lists
for www in w.split(' '):
if (www != 'ESPN') and (www != ''):
if www[0].isupper():
wupp.append(www)
for sss in s.split(' '):
if (sss != 'Yahoo') and (sss != ''):
if sss[0].isupper():
supp.append(sss)
# Once one of the proper nouns are not in the opposite list, no more overlap
for sss in supp:
if sss not in wupp:
strue = 0
for www in wupp:
if www not in supp:
wtrue = 0
# If there is a perfect subset, then similarity works
if (strue == 1) or (wtrue == 1):
simtoken = 1
Now, it’s reasonable to expect that some tweets may slip through the cracks for whatever reason if we set too high a threshold for similarity. In order to do this, we’re going to compare the sets of capitalized words (typically proper nouns) in each tweet and see if one set is a perfect subset of the other. The wupp and supp lists serve to store all the proper nouns from each tweet, and the wtrue and strue variables serve as flags that get toggled off if we find any dissimilarity between the two sets of capitalized words. The www[0].isupper() call just checks the first character in each word and returns True if that character is in upper case. And as a final note, we only really are digging for proper nouns that are relevant to the content of the tweet. Obviously, the two company names for the rival reporters will be different, so we don’t want to let that get in the way of our similarity matching.
# If there is a similarity between the tweets found...
if simtoken == 1:
# Debug statements
print "-s-", s
print "+w+", w
# Wrap final functionality into exception handler
try:
# Shams got it first
if ss.created_at < ww.created_at:
diff = (ww.created_at - ss.created_at).total_seconds()
# A fairly non-elegant scorekeeper method
with open("shamwoj_tracker.txt", 'r') as myFile:
dataLines = myFile.readlines()
tracks = dataLines[0].split(' || ')
shamscore = float(tracks[0].split(',')[0])
wojscore = float(tracks[0].split(',')[1])
margin = float(tracks[1])
battles = float(tracks[2])
# Update the scorekeeper
shamscore += 1
margin += diff
battles += 1
with open("shamwoj_tracker.txt", 'w') as myFile:
myFile.write(str(shamscore) + "," + str(wojscore) + " || " + str(margin) + " || " + str(battles))
api.update_status("Shams got it first by " + str(int(diff)) + " seconds. \n" +
"Scoreboard: Shams " + str(int(shamscore)) + " | Woj " + str(int(wojscore)) +
"\n" + "Avg Margin: " + str(abs(int(margin/battles))) + " seconds" + "\n" +
" https://twitter.com/ShamsCharania/status/" + str(ss.id))
# Woj got it first
elif ss.created_at > ww.created_at:
diff = (ss.created_at - ww.created_at).total_seconds()
# A fairly non-elegant scorekeeper method
with open("shamwoj_tracker.txt", 'r') as myFile:
dataLines = myFile.readlines()
tracks = dataLines[0].split(' || ')
shamscore = float(tracks[0].split(',')[0])
wojscore = float(tracks[0].split(',')[1])
margin = float(tracks[1])
battles = float(tracks[2])
# Update the scorekeeper
wojscore += 1
margin -= diff
battles += 1
with open("shamwoj_tracker.txt", 'w') as myFile:
myFile.write(str(shamscore) + "," + str(wojscore) + " || " + str(margin) + " || " + str(battles))
api.update_status("Woj got it first by " + str(int(diff)) + " seconds. \n" +
"Scoreboard: Shams " + str(int(shamscore)) + " | Woj " + str(int(wojscore)) +
"\n" + "Avg Margin: " + str(abs(int(margin/battles))) + " seconds" + "\n" +
" https://twitter.com/wojespn/status/" + str(ww.id))
# They tied - what the hell
elif ss.created_at == ww.created_at:
api.update_status("By god, it's like they're the same person - a tie! \n" +
" https://twitter.com/ShamsCharania/status/" + str(ss.id))
# Remove the tweet from the lists so we don't recheck them
sham_tweets.remove(ss)
woj_tweets.remove(ww)
# Use exception handler to not re-post tweets or matches
except tweepy.TweepError:
# Remove the tweets still, this just means we've already posted about them
sham_tweets.remove(ss)
woj_tweets.remove(ww)
pass
Don’t be daunted by the wall of code here. Most of it is actually fairly simple and straightforward, and some of it is just repetition (look, if I can do it, you can do it). This is the part where we tweet about who won if our tweet similarity flag is set to 1 – we found a pair of matching tweets!
It’s essential that we wrap the above code in an exception handler if we care about the health of our bot and don’t want it to crash for avoidable reasons (namely, repeating or duplicating previous tweets, which the Twitter API really doesn’t like). The Shams got it first and Woj got it first blocks are, for all practical intents and purposes, the same block, just slightly tweaked, so we’ll just walk through one of them. We’ll know which loop to enter because the created_at property of the tweet object will allow us to check who actually won.
The shamwoj_tracker.txt file is mind-numbingly simple. It’s just one line that looks like this:
2.0,1.0 || 981.0 || 3.0
You’ll want to set all those numbers to zeros when you initialize your bot, but essentially this was the best solution I could come up with on the spot to have a global scorekeeper that would persist independent of the script calls. Could I have just stored it as variables in the same master script? Maybe, but that felt like a somehow even less elegant and adaptable solution than the above. I intend to add on more features to my bot and when I do that, I’ll likely split each functionality into its own independent script, in which case it will be better to have a non-hardcoded scorekeeper.
The first two integers of the tracker are the scores for Shams and Woj, respectively. The double pipes serve as delimiters to help us easily parse the line. The middle number is the total margin (how many seconds have elapsed in total between each pair of similar tweets – subtracted if Woj beat Shams and additive if Shams beat Woj). The final number is the number of “battles” that have been waged, which is both nice to track and helps us calculate the average margin of victory. The rest of the lines that iterate the scorekeeper should be pretty easy to follow.
We read in the scorekeeper, iterate our internal variables based on the most recent event, then write those updates back to the scorekeeper. After all that hard work, we get to finally post the tweet! The tweet will inform us of who won the battle if there were similar tweets, by how much time, the score so far, and the average margin of victory so far, while quote tweeting the victor’s original tweet. I don’t even know what I would do, honestly, if both of them tied. I don’t think I’ve ever seen that happen before. The final step here is to remove the pair of tweets from the original lists so that we don’t repeat ourselves and check them again. Just good practice to clean up after ourselves, considering the mess we’ve made, y’know?
####################
# Execution block
####################
c = 0
while True:
# functions to run
shamwoj()
# testers for now, will remove after a beta deploy period
c += 1
api.update_status("TESTING HEROKU" + str(c))
# wake up to potentially tweet only once every 3 hours
timer.sleep(10800)
The execution block, to finally release our glorious functions into the real world. Using the Timer, we’ll make sure to only run the ShamWoj function once every 3 hours (the Timer object takes its input in seconds), just as we originally planned, and let our good bot take a nap in the meantime.
(I was trying to think of a good pun or metaphor to place here at the end of this section, but ~3700 words in, I’m starting to run out of ideas, so just enjoy this picture of Warriors shooting guard and human torch Klay Thompson with his very good dog Rocco.)

Deploying Our Bot
So we’ve now got an awesome bot that does cool things. Great. Hopefully, you’re not planning to go click the “run” button yourself every three hours or let your computer run this one script till kingdom come. This is exactly where Heroku swoops in for the win, allowing us to deploy our bot on one of their dynos, which are virtualized containers that can be custom-equipped to run the programs which we wish to load onto them. Plus it’s free for light usage (which this is, at least to start)! I’ve used Heroku before for web apps but never for discrete bots, or what Heroku calls as “workers.” I followed the instructions laid out in this article, but below is a brief overview of the steps as well.
- Make sure you have a Heroku account. Basically free points on this one.
- Follow the setup instructions listed here and ensure that you can log into Heroku from your command line.
- Aside from your actual scripts and satellite files, you’ll need a few other files that tell Heroku what to actual do with the files you’ll load onto the dyno. The first is a procfile. You can find an example of a procfile in this sample git repo. Download it into whatever directory you plan on placing your bot into. Open it, and overwrite it with the following line (with the name of your own main script in place of course). The worker tells Heroku that we’re going to use it to continually run a script rather than host a website.
-
worker: python basketbot-prod.py
- The next file you’ll need is one named exactly as requirements.txt. This file will tell Heroku which modules and packages to install (Quick note, you don’t need to specify the Time module, since it’s a pre-installed top level package. You’ll run into errors anyway if you try.). Here’s an example of what each line in this file should look like, specifying the name of the package and the version number:
-
tweepy==3.6.0
- If you’re using a different version of Python other than the standard 3.6, you’ll need to create a runtime.txt file and simply write the following line (note that Heroku doesn’t support any version of Python under 2.7):
-
python-2.7.15
- That’s pretty much all you’ll need to get started! With all the files in one directory, navigate to that folder in your terminal console, if you’re not there already, and run the following command:
-
heroku create
- Your application environment is ready! The final step is to load your files into there. Heroku uses git to maintain and manage your repository of files so make sure that you’re familiar with how git works. To get started, you’ll need to run the holy trinity of git commands: add, commit, and push to master.
Your bot should now be active! Depending on how things were initialized, you may want to just quickly peek in on your app’s resources page in the Heroku portal and ensure that your worker is turned on.

If you feel something is off – try a heroku restart command in the console and give it a jolt. But all in all, your bot should now be free to roam the Twitter-verse! As you update the scripts, just push them to your dyno via git, and have fun expanding and creating something truly special.
I suppose to close things off, wrap it up, tie it with a bow as it were, this is the part where I say something sort of like a motivational disclaimer about about how this was meant to be a quick and dirty bot that I could cobble together in a day and how perfect is the enemy of good – let’s start with something dirty and functional and then iterate from there together. I’m glad to have been able to share the process of creating my first ever Twitter bot with you, and feel free to drop me a note to provide feedback on how to do it even better or just tell me where I (probably) did something terrible. Mutual sharing and collaboration is how we all improve and learn, after all.
Oh, and I’d be remiss if I did not plug my own actual in-production bot: Beasy Woople.
